%20(2).png)
Qui bénéficie vraiment de l’IA : les Entreprises ou les Employés ? À vous d’en juger...
Outil individuel ou levier stratégique, l’IA transforme le travail. Qui, des employés ou des entreprises, en bénéficie le plus ?

Il existe deux façons complètement différentes d’utiliser l’IA :
- Les employés l’utilisent personnellement comme un outil (via des plateformes comme Copilot, Claude, ChatGPT et autres),
- Les entreprises l’utilisent sous leur contrôle pour automatiser des processus et transformer la performance globale.
Alors, quelle est la différence ?
Dans le premier cas, l’IA devient une extension individuelle :
Chaque employé peut interagir avec l’IA sur de multiples plateformes pour gagner en productivité, comme le fait la majorité, ou encore disposer d’un « double numérique » pour déléguer complètement certaines tâches à l’IA.
Par exemple : un employé peut connecter directement son compte courriel (Outlook, Gmail, etc.) à une plateforme comme n8n pour automatiser l’envoi de courriels ou gérer des tâches répétitives. Et même si l’entreprise impose l’utilisation de Microsoft Copilot, plusieurs employés continuent d’utiliser des solutions non officielles, comme des comptes gratuits sur d’autres plateformes plus performantes, afin de réaliser des tâches que Copilot ne permet pas.
Il sera de plus en plus simple pour un employé de créer son propre avatar, puisqu’il est déjà possible aujourd’hui de gérer les courriels, de passer des appels, de manipuler des documents ou encore d’exécuter des tâches spécifiques via de multiples plateformes. On peut même imaginer qu’un jour, un avatar pourra émettre la voix de l’employé et générer une vidéo pour participer à des réunions sans que celui-ci ne soit réellement présent.
Le Model Context Protocol (MCP) est un protocole ouvert qui standardise la façon dont les modèles d’IA communiquent avec des données externes et des outils — un peu comme un port USB‑C pour les IAs. Il facilite l’intégration avec des plateformes comme n8n par exemple. Avec des systèmes d’échange ainsi simplifiés, le futur s’annonce à la fois plus accessible et plus riche en fonctionnalités pour tous ceux qui s’appuient sur ce genre de modèle.
Résultat :
Le principal atout de cette approche est son coût réduit pour le développement de la solution dû à son modèle d’affaire SaaS. Mais elle présente un inconvénient majeur : l’entreprise ne maîtrise pas du tout ses données, ce qui peut poser des risques sérieux, notamment en matière de sécurité et de confidentialité.
De plus, il peut même être impossible de savoir qui a réellement accès aux données, celles-ci pouvant transiter par une série de tiers avant d’arriver dans les mains de ChatGPT ou d’un autre modèle. Même pour les entreprises contrôlant les modèles d’IA, comme OpenAI (ChatGPT), il n’est pas toujours clair que vos données ne soient pas utilisées pour entraîner de nouveaux modèles. La seule entreprise qui clarifie cela légalement est xAI, la société d’Elon Musk qui détient le modèle Grok. La sécurité et la confidentialité des données constituent donc un enjeu majeur avec cette approche.

Dans le deuxième cas, l’IA est mise au service direct de l’organisation :
L’IA peut être déployée de manière formelle dans l’entreprise, sous la supervision du comité de direction, avec des règles strictes de gouvernance et de sécurité. Cette méthode est basée sur la mise à disposition d’une architecture qui appartient à l’entreprise. Plusieurs architectures sont possibles, l’une d’elles reposant sur l’usage d’une instance EC2 (Elastic Compute Cloud) sur AWS : il s’agit d’un serveur virtuel entièrement administré par l’entreprise. Celui-ci peut être connecté à d’autres services AWS comme :
- Amazon S3, pour stocker en toute durabilité et haute disponibilité les données et fichiers,
- Amazon Bedrock, un service géré qui donne accès à des modèles de base (Foundation Models, FMs) développés par différents fournisseurs (Anthropic, Cohere, Meta, Amazon, etc.).
Ces modèles peuvent être personnalisés en toute sécurité (fine-tuning, RAG), sans nécessiter de gestion de l’infrastructure sous-jacente. L’ensemble de l’architecture reste totalement encapsulé dans votre périmètre AWS, avec :
- Un contrôle complet sur la sécurité et la gouvernance des données,
- Des mécanismes comme les VPC endpoints pour communication privée,
- La mise en place de garde-fous (guardrails), journaux d’audit, chiffrement des données en transit et au repos, etc.
C’est comme une “boîte noire” sur mesure, sécurisée et dédiée, conçue pour supporter vos applications IA, sans fuite de données vers des tiers.
Voici ici un exemple concret d’utilisation :
Vous souhaitez automatiser un agent IA chargé de répondre à des courriels entrants et de compléter le contenu sur une application web client. Dans ce cas :
- L’instance EC2 héberge une application (par exemple via Entra) qui accède à la messagerie Outlook de l’entreprise et interagit avec l’API de l’application web.
- Un modèle LLM ou autres modèles (pour gérer différent use case spécifique) sur Bedrock, entraîné avec vos données et votre expertise, génère les réponses aux courriels et remplit l’application conformément aux critères définis.
- Les données restent confinées au sein de votre infrastructure AWS, sans échange avec des systèmes tiers.
Résultat :
C’est beaucoup plus coûteux à développer puisque cette méthode nécessite un intégrateur spécialisé en IA comme Angel Softwares par exemple, cependant l’entreprise a un contrôle total sur ses données. De la même façon qu’il est possible de contrôler ses bases de données, il est possible de maîtriser les flux de données vers les modèles d’IA, l’entraînement des modèles, ainsi que le résultat des traitements.
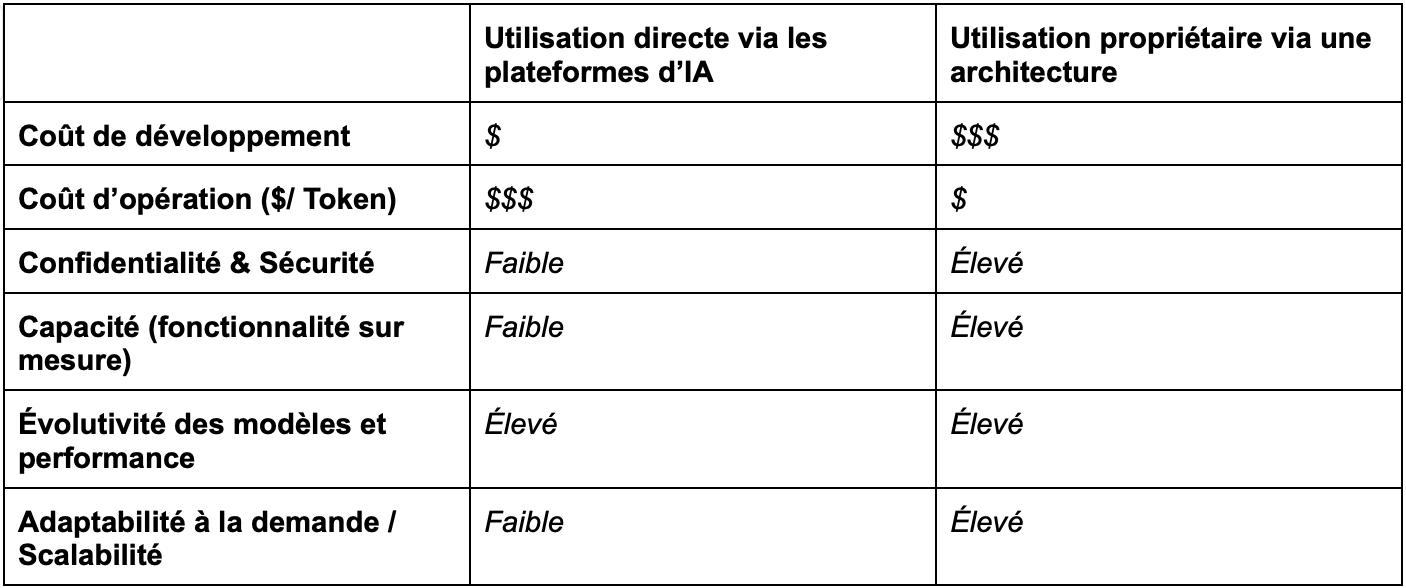
Voici un tableau comparatif des deux méthodes ;
Il faut aussi considérer les risques d’abus : même si une entreprise interdit l’usage d’outils externes et impose uniquement Copilot, certains employés pourraient quand même payer un abonnement personnel à une autre plateforme pour automatiser une grande partie de leur travail.
Selon une étude de KPMG de novembre 2024, 24 % des utilisateurs affirmaient avoir saisi des données confidentielles dans des plateformes publiques d’IA générative, par exemple liées aux ressources humaines ou à la chaîne d’approvisionnement, et 19 % disaient avoir saisi des données financières privées concernant leur employeur (contre 12 % auparavant). Cela illustre que ce type de contournement est une réalité bien présente.
À l’époque, les outils n’étaient pas aussi développés qu’aujourd’hui et ne permettaient pas d’automatiser des tâches comme c’est désormais possible, par exemple pour gérer automatiquement une boîte de courriels. Les risques de fuite de données deviendront de plus en plus élevés avec l’élargissement de l’accès à ces outils. De plus, cela soulève une question délicate : pourquoi l’entreprise paierait-elle un salaire complet si une partie, voire la totalité du travail, est déléguée à une IA payée par l’employé lui-même ?
On comprend donc que la vraie question n’est pas si l’IA deviendra indispensable, mais plutôt, À QUI IL PROFITERA LE PLUS ?